MongoDB集群搭建
一. 单机版搭建
软件环境:
Linux: CentOS7_5_64_org
MongoDB: mongodb-linux-x86_64-rhel70-4.0.2.tgz
1.1.安装包下载
官方网址: https://www.mongodb.com/download-center/v2/community
1.2.MongoDB安装
1.2.1.服务器环境配置
1
2
3
4
5
6
7
8
9
10
11
12
#在usr下创建mongodb文件夹
cd /usr/
mkdir mongodb
#解压文件
tar -xzvf mongodb-linux-x86_64-rhel70-4.0.2.tgz
#添加环境变量
vi /etc/profile
#在文件末尾插入如下内容
export MONGODB_HOME=/usr/mongodb/mongodb-4.0.2
export PATH=$PATH:$MONGODB_HOME/bin
#保存后立即生效,执行命令如下
source /etc/profile
1.2.2.MongoDB配置
准备工作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#创建数据库文件存放路径
cd /usr/mongodb/mongodb-4.0.2
mkdir data
chmod -R 777 data
#创建日志文件
cd /usr/mongodb/mongodb-4.0.2
mkdir logs
cd logs
touch mongodb.log
#创建启动文件
cd /usr/mongodb/mongodb-4.0.2
mkdir etc
cd etc
touch mongodb.conf
编辑启动文件
1
vi mongodb.conf
在文件中插入如下内容(支持yml格式)
详细配置,可参见官方:
https://docs.mongodb.com/manual/reference/configuration-options/
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#mongod.conf
#for documentation of all options, see:
#http://docs.mongodb.org/manual/reference/configuration-options/
#where to write logging data.
systemLog:
destination: file #日志存储方式
logAppend: true #日志方式为追加
path: /usr/mongodb/mongodb-4.0.2/logs/mongodb.log #日志目录
#Where and how to store data.
storage:
dbPath: /usr/mongodb/mongodb-4.0.2/data #数据库文件目录
journal:
enabled: true #启用日志功能
#engine:
#mmapv1:
#wiredTiger:
#how the process runs.
processManagement:
fork: true #true表示在后台启动
# pidFilePath: /usr/mongodb/mongodb-4.0.2/pid/mongod.pid
# timeZoneInfo: /usr/mongodb/mongodb-4.0.2/share/zoneinfo
#network interfaces.
net:
bindIp: 192.168.3.226 #mongodb所绑定的IP
port: 27017 #mongodb所占用的端口
#security:
#operationProfiling:
#replication:
# replSetName: test-rc #副本集的名称
#sharding:
#Enterprise-Only Options.
#auditLog:
#snmp:
security: #开启登录验证
authorization: enabled
1.2.3.启动MongoDB
1
2
3
4
5
6
#切换到bin目录下
cd /usr/mongodb/mongodb-4.0.2/bin/
#启动数据库
./mongod -f ../etc/mongodb.conf
#访问数据库
./mongo --host 192.168.3.226
1.2.3.设置用户和密码
1.创建用户管理员账户
1
2
3
4
5
6
7
8
9
10
11
12
13
#切换到bin目录下
cd /usr/mongodb/mongodb-4.0.2/bin/
#访问数据库
./mongo --host 192.168.3.226
#创建用户、密码和访问权限``
> use admin
> db.createUser(
{
user: "adminUser", # 用户名
pwd: "adminPass", # 密码
roles: [{ role: "userAdminAnyDatabase", db: "admin" }] # 权限,最高权限
}
)
管理员创建成功,现在拥有了用户管理员,然后,断开 mongodb 连接,关闭数据库。
2.Mongodb用户验证登陆
1.切换到bin目录下
1
cd /usr/mongodb/mongodb-4.0.2/bin/
2.访问数据库
现在有两种方式进行用户身份的验证
第一种
客户端连接时,指定用户名,密码,db名称
1
./mongo --port 27017 -u "adminUser" -p "adminPass" –authenticationDatabase "admin"
第二种
客户端连接后,再进行验证。
1
2
3
./mongo --port 27017
> use admin
> db.auth("adminUser", "adminPass")
输出 1 表示验证成功。
3.创建普通用户
过程类似创建管理员账户,只是role有所不同。
1
2
3
4
5
6
7
8
9
> use foo
> db.createUser(
{
user: "simpleUser", # 用户名
pwd: "simplePass", # 密码
roles: [ { role: "readWrite", db: "foo" }, # 权限:读写数据库foo
{ role: "read", db: "bar" } ] # 权限:只读数据库bar
}
)
现在我们有了一个普通用户。
注意
use foo表示用户在foo库中创建,就一定要foo库验证身份,即用户的信息跟随数据库。比如上述 simpleUser用户虽然有bar库的读取权限,但是一定要先在foo库进行身份验证,直接访问会提示验证失败。
1
2
3
4
> use foo
> db.auth("simpleUser", "simplePass")
> use bar
> show collections
还有一点需要注意,如果admin库没有任何用户的话,即使在其他数据库中创建了用户,启用身份验证时,默认的连接方式依然会有超级权限。
4.权限说明
Read:允许用户读取指定数据库。readWrite:允许用户读写指定数据库。dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile。userAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户。clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限。readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限。userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限。dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。root:只在admin数据库中可用。超级账号,超级权限。
二.副本集版搭建
2.1.概述
2.1.1.组成
Mongodb副本集(replica set)由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary通过oplog来同步Primary的数据,保证主节点和从节点数据的一致性,副本集在完成主从复制的基础上,通过心跳机制,一旦primary节点出现宕机,则触发选举一个新的主节点,剩下的secondary节点指向新的primary,时间应该在10-30s内完成感知primary节点故障,实现高可用数据库集群。
特点:
Primary是唯一的,但不是固定的;- 由大多数据原则保证数据的一致性;
- 从库无法写入(默认情况下,不使用驱动连接时,也是不能查询的);
- 相对于传统的主从结构,副本集可以自动容灾。
2.1.2.原理
角色(按是否存储数据划分):
Primary:主节点,由选举产生,负责客户端的写操作,产生oplog日志文件;Secondary:从节点,负责客户端的读操作,提供数据的备份和故障的切换;Arbiter:仲裁节点,只参与选举的投票,不会成为primary,也不向Primary同步数据,若部署了一个2个节点的副本集,1个Primary,1个Secondary,任意节点宕机,副本集将不能提供服务了(无法选出Primary),这时可以给副本集添加一个Arbiter节点,即使有节点宕机,仍能选出Primary。
角色(按类型区分):
Standard(标准):这种是常规节点,它存储一份完整的数据副本,参与投票选举,有可能成为主节点;Passive(被动):存储完整的数据副本,参与投票,不能成为活跃节点。Arbiter(投票):仲裁节点只参与投票,不接收复制的数据,也不能成为活跃节点。
注:每个参与节点(非仲裁者)有个优先权(0-1000),优先权(priority)为0则是被动的,不能成为活跃节点,优先权不为0的,按照由大到小选出活跃节点,优先值一样的则看谁的数据比较新。
2.1.3.选举
每个节点通过优先级定义出节点的类型(标准、被动、投票);
标准节点通过对比自身数据进行选举出peimary节点或者secondary节点。
影响选举的因素:
心跳检测:副本集内成员每隔两秒向其他成员发送心跳检测信息,若10秒内无响应,则标记其为不可用;连接:在多个节点中,最少保证两个节点为活跃状态,如果集群中共三个节点,挂掉两个节点,那么剩余的节点无论状态是primary还是处于选举过程中,都会直接被降权为secondary。
触发选举的情况:
- 初始化状态
- 从节点们无法与主节点进行通信
- 主节点辞职
主节点辞职的情况:
- 在接收到replSetStepDown命令后;
- 在现有的环境中,其他secondary节点的数据落后于本身10s内,且拥有更高优先级;
- 当主节点无法与群集中多数节点通信。
注:当主节点辞职后,主节点将关闭自身所有连接,避免出现客户端在从节点进行写入操作
2.2.部署
副本集的最小体系结构有三个成员。三成员副本集可以是包含三个保存数据的成员,也可以是包含两个保存数据和一个仲裁的成员。
两种结构的图示,如下:
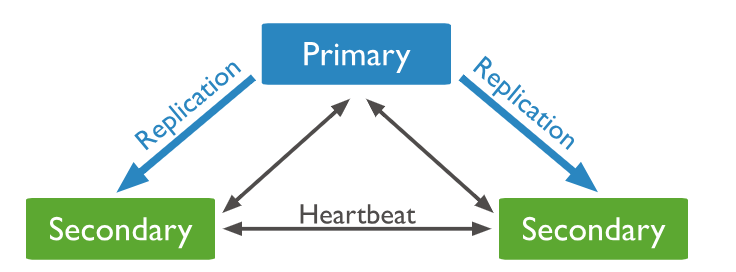
- 一个主要成员。
- 两个辅助成员。这两个辅助成员都可以成为选举中的主要成员。
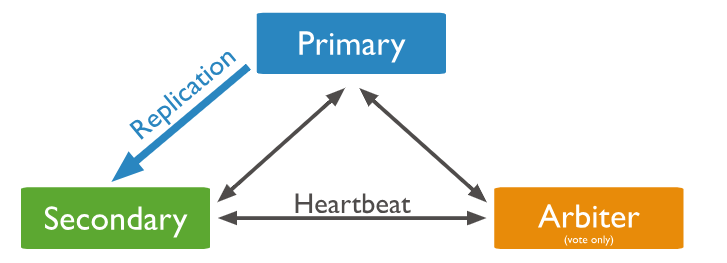
- 一个主要成员。
- 一个辅助成员。可以成为选举的主要成员。
- 一个仲裁者。仲裁者只在选举中投票。
2.2.1.配置文件
启用配置文件中的replication项,设置副本集的名称,三台名称相同;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#mongod.conf
#for documentation of all options, see:
#http://docs.mongodb.org/manual/reference/configuration-options/
#where to write logging data.
systemLog:
destination: file #日志存储方式
logAppend: true #日志方式为追加
path: /usr/mongodb/mongodb-4.0.2/logs/mongodb.log #日志目录
#Where and how to store data.
storage:
dbPath: /usr/mongodb/mongodb-4.0.2/data #数据库文件目录
journal:
enabled: true #启用日志功能
#engine:
#mmapv1:
#wiredTiger:
#how the process runs.
processManagement:
fork: true #true表示在后台启动
# pidFilePath: /usr/mongodb/mongodb-4.0.2/pid/mongod.pid
# timeZoneInfo: /usr/mongodb/mongodb-4.0.2/share/zoneinfo
#network interfaces.
net:
bindIp: 192.168.3.226 #mongodb所绑定的IP
port: 27017 #mongodb所占用的端口
#security:
#operationProfiling:
replication:
replSetName: "repl" #副本集的名称
#sharding:
#Enterprise-Only Options.
#auditLog:
#snmp:
2.2.2.初始化副本集
1.切换到bin目录下
1
cd /usr/mongodb/mongodb-4.0.2/bin/
2.启动数据库
1
./mongod -f ../etc/mongodb.conf
3.访问数据库,随机登录一台服务器
1
./mongo --host 192.168.3.226
4 启动副本集
1
2
3
4
5
6
7
8
> rs.initiate( {
_id : "repl",
members: [
{ _id: 0, host: "192.168.3.226:27017" },
{ _id: 1, host: "192.168.3.227:27017" },
{ _id: 2, host: "192.168.3.231:27017" }
]
})
5.查看副本集配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
> rs.conf()
#输出结果:
{
"_id" : "repl",
"version" : 1,
"protocolVersion" : NumberLong(1),
"writeConcernMajorityJournalDefault" : true,
"members" : [
{
"_id" : 0,
"host" : "192.168.3.226:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "192.168.3.227:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "192.168.3.231:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("5bc047d5dbce10187d4a0863")
}
}
6.确保副本集具有主副本
1
> rs.status()
7.查看主节点
1
> rs.isMaster()
2.2.3.测试副本集
主副本登录
1
2
3
4
5
6
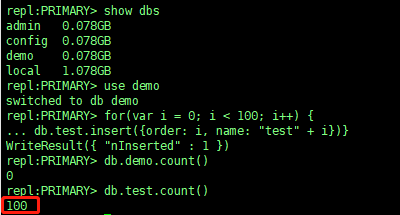
./mongo --host 192.168.3.226
#在插入100条数据
> show dbs #查看存在的库
> use demo #切换到demo库
> for(var i = 0;i < 100; i++){db.test.insert({order:i,name:"test"+i})}
> db.test.count() #查看插入条数
 从副本登录
从副本登录
1
2
3
4
5
./mongo --host 192.168.3.227
> rs.slaveOk() #开启从副本查询功能,从节点默认情况下是拒绝读取
> show dbs #查看存在的库
> use demo #切换到demo库
> db.test.count() #查看插入条数
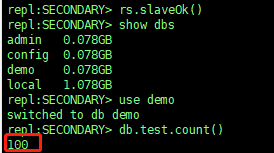 注:从副本查询数量和主副本相同,则说明集群搭建成功。
注:从副本查询数量和主副本相同,则说明集群搭建成功。
三.分片版搭建
3.1.概述
什么是分片
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存,而将压力转移到磁盘IO上。
MongoDB分片是使用多个服务器存储数据的方法,以支持巨大的数据存储和对数据进行操作。分片技术可以满足MongoDB数据量大量增长的需求,当一台MongoDB服务器不足以存储海量数据或者不足以提供可接受的读写吞吐量时,我们就可以通过在多台服务器上分割数据,使得数据库系统能存储和处理更多的数据。
MongoDB分片优势
分片为应对高吞吐量与大数据量提供了方法。
- 使用分片减少了每个分片需要处理的请求数,因此,通过水平扩展,群集可以提高自己的存储容量。比如,当插入一条数据时,应用只需要访问存储这条数据的分片。
- 使用分片减少了每个分片存储的数据。 分片的优势在于提供类似线性增长的架构,提高数据可用性,提高大型数据库查询服务器的性能。当MongoDB单点数据库服务器存储成为瓶颈、单点数据库服务器的性能成为瓶颈或需要部署大型应用以充分利用内存时,可以使用分片技术。
MongoDB分片群集的组成
Shard:分片服务器,用于实际的存储数据库,从MongoDB 3.6开始,必须将分片部署为副本集。Config Server:配置服务器,存储了整个分片群集的配置信息,其中包括chunk信息。mongos:充当查询路由器,提供客户端应用程序和分片集群之间的接口。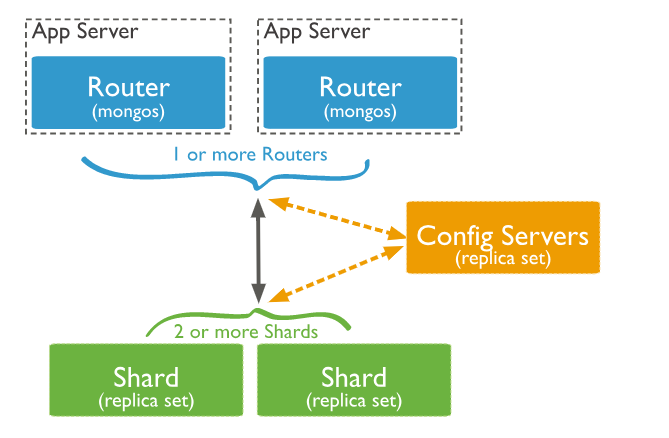
3.2.部署
在生产环境中,确保数据冗余并确保系统具有高可用性。对于生产分片集群部署,请考虑以下事项:
- 将
Config Server部署为3成员。 - 将每个
Shard部署为3个成员。 - 部署一个或多个路由器。